

Mọi người đều thấy rõ ràng rằng các tài liệu rò rỉ của Google và các tài liệu công khai đến từ phiên điều trần chống độc quyền không thực sự cho chúng ta biết một cách chính xác về cách thức xếp hạng của Google hoạt động.
Cấu trúc của kết quả tìm kiếm hữu cơ hiện nay vô cùng phức tạp, chủ yếu là do việc sử dụng máy học. Ngay cả những nhân viên của Google làm việc trên các thuật toán xếp hạng cũng nói rằng: họ còn không thể giải thích tại sao một kết quả lại ở mức một hoặc hai.
Chúng ta không biết được trọng số của nhiều tín hiệu và sự tương tác chính xác.
Tuy nhiên, điều quan trọng là phải làm quen với cấu trúc của công cụ tìm kiếm để hiểu rõ lý do tại sao các trang được tối ưu hóa tốt không được xếp hạng hoặc ngược lại, rằng tại sao các kết quả có vẻ ngắn và không được tối ưu hóa đôi khi lại được xuất hiện ở đầu bảng xếp hạng.
Thực tế, rất khó để vẽ ra một bức tranh rõ ràng về cấu trúc của hệ thống. Thông tin trên web khá khác nhau về cách diễn giải và đôi khi còn khác nhau về cả thuật ngữ, mặc dù chúng có cùng một ý nghĩa.
Ví dụ: Hệ thống chịu trách nhiệm xây dựng SERP (trang kết quả tìm kiếm) tối ưu hóa việc sử dụng không gian được gọi là Tangram. Tuy nhiên, trong một số tài liệu của Google, nó cũng được gọi là Tetris, có lẽ là ám chỉ đến trò chơi nổi tiếng này.
Bài viết này giúp phân tích chuyên sâu về cách thức hoạt động của hệ thống xếp hạng phức tạp của Google và các thành phần như Twiddlers và NavBoost ảnh hưởng đến kết quả tìm kiếm. Nó thể hiện nỗ lực tốt nhất của tôi và kết quả là những gì bạn thấy ở đây.
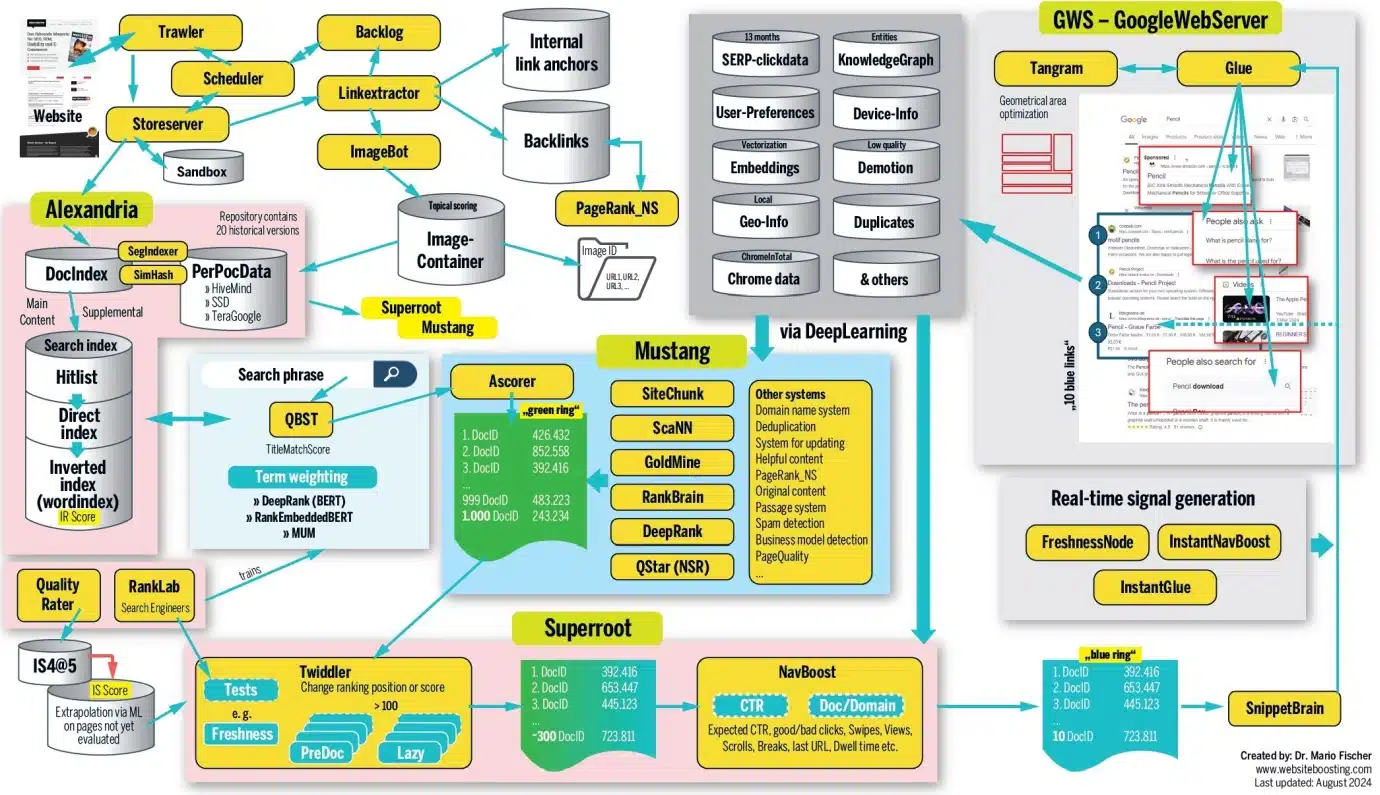
Tổng quan đồ họa về cách xếp hạng của Google hoạt động, được tạo bởi tác giả
Một tài liệu mới đang chờ Googlebot ghé thăm
Khi bạn xuất bản một trang web mới, nó sẽ không được lập chỉ mục ngay lập tức. Trước tiên, Google phải tiến hành nhận biết URL. Điều này thường xảy ra thông qua sơ đồ trang web được cập nhật hoặc thông qua các liên kết được đặt ở đó từ một URL đã biết.
Các trang được truy cập thường xuyên, như trang chủ, sẽ tự nhiên thu hút được sự chú ý của Google nhanh hơn thông tin liên kết này.
Hệ thống trawler lấy nội dung mới và theo dõi thời điểm truy cập lại URL để kiểm tra cập nhật. Điều này được quản lý bởi một thành phần gọi là trình lập lịch. Máy chủ lưu trữ quyết định URL sẽ được chuyển tiếp hay được đặt trong hộp cát.
Google phủ nhận sự tồn tại của hộp cát này, nhưng thông qua các rò rỉ gần đây đã cho thấy rằng: các trang web spam và các trang web có giá trị thấp sẽ được đặt ở đó. Google cũng thường chuyển tiếp một số thư rác, có thể là để phân tích thêm, giúp đào tạo cho các thuật toán của mình.
Các liên kết đến hình ảnh được chuyển đến ImageBot, và chúng được đặt trong một vùng chứa hình ảnh. Nếu một trang web có nhiều lưu lượng truy cập hơn, tần suất thu thập dữ liệu này sẽ tăng lên (ClientTrafficFraction).
Alexandria: Thư viện lớn
Alexandria là hệ thống lập chỉ mục của Google, chỉ định một DocID duy nhất cho từng phần nội dung. Nếu nội dung đã được biết đến, như trong trường hợp bị trùng lặp, thì ID mới sẽ không được tạo ra; thay vào đó, URL sẽ được liên kết với DocID hiện có.
Quan trọng: Google phân biệt giữa URL và tài liệu. Một tài liệu có thể bao gồm nhiều URL có nội dung tương tự, bao gồm các phiên bản ngôn ngữ khác nhau, nếu như chúng được đánh dấu đúng cách. Các URL từ các miền khác cũng sẽ được sắp xếp ở đây. Tất cả các tín hiệu từ các URL này được áp dụng thông qua DocID chung.
Đối với các nội dung trùng lặp, Google sẽ tiến hành chọn phiên bản “gốc” để xuất hiện trong bảng xếp hạng tìm kiếm. Điều này cũng giải thích tại sao các URL khác đôi khi có thể xếp hạng tương tự; việc xác định URL “gốc” có thể được thay đổi theo thời gian.

Hình 1: Alexandria thu thập URL cho một tài liệu.
Vì chỉ có một phiên bản tài liệu này trên web nên nó được cấp DocID riêng.
Vì tài liệu của chúng tôi chứa từ “pencil” nhiều lần, nên hiện tại nó được liệt kê trong mục lục từ với DocID trong mục “pencil”.
Các phân đoạn riêng lẻ của trang web của chúng tôi được tìm kiếm các cụm từ khóa có liên quan và được đẩy vào chỉ mục tìm kiếm. Ở đó, “danh sách truy cập” (gồm tất cả các từ quan trọng trên trang) trước tiên được gửi đến chỉ mục trực tiếp, tóm tắt các từ khóa xuất hiện nhiều lần trên mỗi trang.
Các cụm từ khóa riêng lẻ sẽ được tích hợp vào danh mục từ của chỉ mục đảo ngược (chỉ mục từ). Từ “pencil” và tất cả các tài liệu quan trọng có chứa từ này đều đã được liệt kê ở đó.
DocID được gán một điểm IR (truy xuất thông tin) được tính toán theo thuật toán cho “pencil”, sau đó được sử dụng để đưa vào Danh sách đăng. Ví dụ, trong tài liệu của chúng tôi, từ “pencil” đã được đánh dấu in đậm trong văn bản và được chứa trong H1 (được lưu trữ trong AvrTermWeight ). Các tín hiệu như vậy và các tín hiệu khác làm tăng điểm IR.
Google di chuyển các tài liệu được coi là quan trọng đến HiveMind, là bộ nhớ chính. Google sử dụng cả SSD nhanh và HDD thông thường (gọi là TeraGoogle) để lưu trữ thông tin lâu dài mà không cần truy cập nhanh. Tài liệu và tín hiệu sẽ được lưu trữ trong bộ nhớ chính.
Theo các chuyên gia, trước khi bùng nổ AI, khoảng một nửa số máy chủ web trên thế giới được lưu trữ tại Google. Một mạng lưới rộng lớn các cụm được kết nối cho phép hàng triệu đơn vị bộ nhớ chính hoạt động cùng nhau. Một kỹ sư của Google đã từng lưu ý tại một hội nghị rằng, về mặt lý thuyết thì bộ nhớ chính của Google có thể lưu trữ toàn bộ web.
Các liên kết, bao gồm cả liên kết ngược, được lưu trữ trong HiveMind dường như có trọng số lớn hơn đáng kể. Ví dụ, các liên kết từ các tài liệu quan trọng được coi trọng hơn nhiều, trong khi các liên kết đến từ URL trong TeraGoogle (HDD) có thể được coi trọng ít hơn hoặc có thể không được xem xét.
– Gợi ý: Cung cấp cho tài liệu của bạn các giá trị ngày hợp lý và nhất quán. BylineDate (ngày trong mã nguồn), syntaticDate (ngày trích xuất từ URL và/hoặc tiêu đề) và semanticDate (lấy từ nội dung có thể đọc được) được sử dụng, trong số những giá trị khác.
– Việc làm giả tính thời sự bằng cách thay đổi ngày chắc chắn có thể dẫn đến việc hạ thứ hạng (hạ cấp). Thuộc tính lastSignificantUpdate sẽ giúp ghi lại thời điểm thay đổi quan trọng cuối cùng được thực hiện đối với một tài liệu. Việc sửa các chi tiết nhỏ hoặc lỗi về đánh máy sẽ không ảnh hưởng đến bộ đếm này.
Thông tin bổ sung và tín hiệu cho mỗi DocID được lưu trữ động trong kho lưu trữ (PerDocData). Nhiều hệ thống sẽ tiến hành truy cập vào đây sau khi cần tinh chỉnh mức độ liên quan. Và 20 phiên bản cuối cùng của một tài liệu được lưu trữ ở đó là điều hữu ích (thông qua CrawlerChangerateURLHistory ).
Google có khả năng đánh giá và thẩm định những thay đổi theo thời gian. Nếu bạn muốn tiến hành thay đổi hoàn toàn nội dung hoặc chủ đề của một tài liệu, về mặt lý thuyết, bạn sẽ cần phải tạo ra 20 phiên bản trung gian để có thể ghi đè lên các tín hiệu nội dung cũ. Đây chính là lý do tại sao việc khôi phục một tên miền đã hết hạn (một tên miền trước đây đã hoạt động nhưng đã bị bỏ rơi hoặc bán, có thể là do mất khả năng thanh toán) không mang lại bất kỳ một lợi thế về xếp hạng nào.
Nếu Admin-C của một tên miền thay đổi và nội dung chủ đề của nó cũng thay đổi cùng lúc, máy có thể dễ dàng nhận ra điều này tại thời điểm này. Sau đó, Google tiến hành đặt tất cả các tín hiệu về 0 và tên miền cũ được cho là có giá trị thì lúc này sẽ không còn mang lại bất kỳ một lợi thế nào so với tên miền mới được đăng ký.
Hình 2: Ngoài các thông tin rò rỉ, các tài liệu bằng chứng từ các phiên điều trần và phiên tòa xét xử của cơ quan tư pháp Hoa Kỳ chống lại Google cũng là nguồn hữu ích để nghiên cứu. Bạn thậm chí còn có thể tìm thấy email nội bộ ở đó.
QBST: Có người đang tìm “pencil”
Khi ai đó nhập “pencil” làm thuật ngữ tìm kiếm trong Google, QBST bắt đầu công việc của mình. Cụm từ tìm kiếm được phân tích và nếu nó chứa nhiều từ, những từ có liên quan sẽ được gửi đến chỉ mục từ để truy xuất.
Quá trình đánh giá trọng số thuật ngữ khá phức tạp, liên quan đến các hệ thống như: RankBrain, DeepRank (trước đây là BERT) và RankEmbeddedBERT. Các thuật ngữ có liên quan, như “pencil”, sau đó được chuyển đến Ascorer để xử lý thêm.
Ascorer: ‘Vòng tròn xanh’ đã được tạo ra
Ascorer lấy 1.000 DocID hàng đầu cho “pencil” từ chỉ mục đảo ngược, được xếp hạng theo điểm IR. Theo các tài liệu nội bộ, danh sách này được gọi là “vòng tròn xanh”. Trong ngành, nó chính là danh sách đăng.
Ascorer là một phần của hệ thống xếp hạng được gọi là Mustang, trong đó quá trình lọc tiếp theo diễn ra thông qua các phương pháp, như: loại bỏ trùng lặp bằng SimHash (một loại dấu vân tay tài liệu), phân tích đoạn văn, hệ thống nhận dạng nội dung gốc và hữu ích, … Mục tiêu chính là tinh chỉnh 1.000 ứng viên xuống chỉ còn “10 liên kết màu xanh” hoặc “vòng tròn màu xanh”.
Tài liệu của chúng tôi về “pencil” hiện có trong danh sách đăng, xếp hạng ở vị trí 132. Nếu không có hệ thống bổ sung, đây sẽ là vị trí cuối cùng của tài liệu.
Superroot: Biến 1.000 thành 10!
Hệ thống Superroot có trách nhiệm xếp hạng lại, thực hiện công việc chính xác là giảm “vòng tròn xanh lá cây” (1.000 DocID) xuống “vòng tròn xanh lam” chỉ gồm có 10 kết quả.
Twiddlers và NavBoost sẽ thực hiện nhiệm vụ này. Có thể sẽ có những hệ thống khác đang được sử dụng ở đây, tuy nhiên thông tin chính xác về chúng là không rõ ràng.
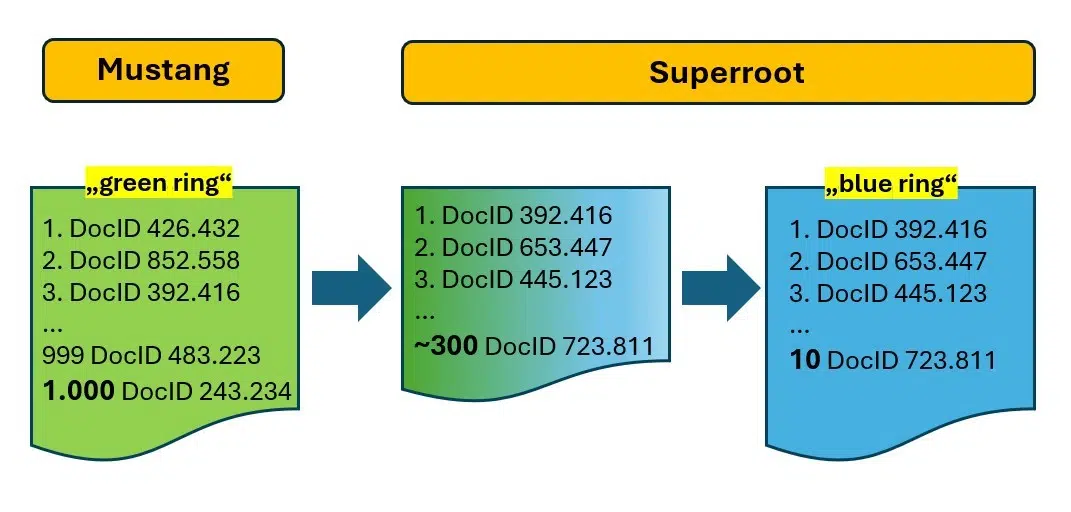
Hình 3: Mustang tạo ra 1.000 kết quả tiềm năng và Superroot lọc chúng xuống còn 10 kết quả.
– Google Caffeine không còn tồn tại ở dạng này nữa. Nó chỉ còn là cái tên.
– Google hiện đang làm việc với vô số dịch vụ vi mô giao tiếp với nhau và tạo ra các thuộc tính cho tài liệu được sử dụng để làm tín hiệu cho nhiều hệ thống xếp hạng và xếp hạng lại khác nhau, đồng thời đào tạo các mạng nơ-ron để đưa ra dự đoán.
Bộ lọc sau bộ lọc: The Twiddlers
Nhiều tài liệu đang chỉ ra rằng có hàng trăm hệ thống Twiddler đang được sử dụng. Mỗi Twiddler sẽ có mục tiêu lọc riêng. Chúng được thiết kế theo cách này vì chúng tương đối dễ tạo và không yêu cầu thay đổi thuật toán xếp hạng phức tạp trong Ascorer.
Việc sửa đổi các thuật toán này là một thách thức và sẽ liên quan đến việc lập kế hoạch và lập trình mở rộng do các tác dụng phụ tiềm ẩn. Ngược lại, Twiddlers hoạt động song song hoặc tuần tự và không biết về các hoạt động của các Twiddlers khác.
Về cơ bản, hiện tại có hai loại Twiddlers.
– PreDoc Twiddlers có thể làm việc với toàn bộ tập hợp gồm hàng trăm DocID, vì chúng hầu như không yêu cầu thông tin bổ sung.
– Ngược lại, Twiddlers thuộc loại “Lazy” thì lại yêu cầu nhiều thông tin hơn, ví dụ, từ cơ sở dữ liệu PerDocData. Điều này sẽ mất nhiều thời gian hơn và phức tạp hơn.
Chính vì vậy, PreDocs sẽ có nhiệm vụ trước tiên chính là giảm danh sách đăng xuống ít mục nhập hơn đáng kể và sau đó bắt đầu bằng bộ lọc chậm hơn. Nó sẽ giúp tiết kiệm được rất nhiều dung lượng tính toán và thời gian.
Một số Twiddler điều chỉnh điểm IR, theo hướng tích cực hoặc tiêu cực, trong khi những Twiddler khác thì lại điều chỉnh vị trí xếp hạng trực tiếp. Vì tài liệu của chúng tôi là mới đối với chỉ mục, và một Twiddler được thiết kế để cung cấp cho các tài liệu mới có cơ hội xếp hạng tốt hơn, ví dụ, nhân điểm IR với hệ số 1,7. Sự điều chỉnh này có thể đưa tài liệu của chúng tôi từ vị trí thứ 132 lên vị trí thứ 81.
Một Twiddler khác thì giúp tăng cường tính đa dạng (striddleCategory) trong SERP bằng cách hạ giá các tài liệu có nội dung tương tự. Và một số tài liệu trước chúng tôi bị mất vị trí của chúng, cho phép tài liệu “pencil” của chúng tôi tăng thêm 12 bậc, lên 69. Ngoài ra, một Twiddler giới hạn số trang blog ở mức ba cho các truy vấn cụ thể sẽ giúp tăng thứ hạng của chúng ta lên 61.
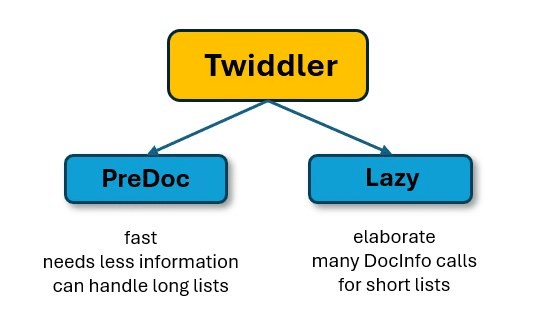
Hình 4: Hai loại Twiddlers – hơn 100 loại trong số đó thu hẹp kết quả tìm kiếm tiềm năng và sắp xếp lại chúng.
Trang của chúng tôi nhận được số không (cho “Có”) cho thuộc tính CommercialScore. Hệ thống Mustang đã xác định được ý định bán hàng ở trong quá trình phân tích. Google có thể biết rằng các tìm kiếm “pencil” thường được theo sau bởi các tìm kiếm được tinh chỉnh như “buy pencil”, nó cho biết ý định thương mại hoặc giao dịch của người dùng. Một Twiddler được thiết kế để tính đến ý định tìm kiếm này sẽ giúp thêm các kết quả có liên quan và tăng trang của chúng tôi lên 20 vị trí, đưa chúng tôi lên 41.
Một Twiddler khác tham gia, thực thi “hình phạt trang ba” giới hạn các trang bị nghi ngờ là thư rác ở thứ hạng tối đa là 31 (Trang 3). Vị trí tốt nhất cho một tài liệu được xác định bởi thuộc tính BadURL – demoteindex , ngăn không cho xếp hạng vượt quá ngưỡng này. Các thuộc tính như DemoteForContent, DemoteForForwardlinks và DemoteForBacklinks được sử dụng cho mục đích này. Các kết quả khác bị hạ cấp, cho phép trang của chúng ta di chuyển lên Vị trí 38.
Một Twiddler cuối cùng đánh giá mức độ liên quan của trang “pencil” của chúng tôi với tên miền của chúng tôi dựa trên các nhúng. Vì trang web của chúng tôi chỉ tập trung vào các công cụ viết, điều này tạo ra nhiều lợi ích cho chúng tôi và tác động tiêu cực đến 24 tài liệu khác.
Ví dụ, một trang web so sánh giá với nhiều chủ đề khác nhau, nhưng có một trang “tốt” về “pencil”. Vì chủ đề của trang này khác biệt đáng kể so với trọng tâm chung của trang web, nên nó sẽ bị Twiddler này tiến hành hạ cấp.
Các thuộc tính như siteFocusScore và siteRadius phản ánh khoảng cách chủ đề này. Và điểm IR của chúng tôi được tăng thêm một lần nữa và các kết quả khác bị hạ cấp, đưa chúng tôi lên Vị trí 14.
Như vậy, Twiddlers phục vụ nhiều mục đích khác nhau. Các nhà phát triển có thể thử nghiệm với các bộ lọc, hệ số nhân hoặc hạn chế vị trí cụ thể mới. Thậm chí có thể xếp hạng một kết quả cụ thể ở trước hoặc sau một kết quả khác.
Theo những tài liệu nội bộ bị rò rỉ của Google cảnh báo rằng: một số tính năng nhất định của Twiddler chỉ nên được sử dụng bởi các chuyên gia và sau khi tham khảo ý kiến của nhóm tìm kiếm cốt lõi.
Ngoài ra, còn có Twiddlers chỉ tạo chú thích và thêm chúng vào DocID trên đường đến SERP. Ví dụ, một hình ảnh sau đó sẽ được xuất hiện trong đoạn trích hoặc tiêu đề hoặc mô tả được viết lại động sau đó.
Nếu bạn thắc mắc tại sao cơ quan y tế quốc gia của nước bạn luôn đứng đầu trong các tìm kiếm về COVID-19 trong thời kỳ đại dịch, thì đó là nhờ vào Twiddler giúp tăng cường các nguồn tài nguyên chính thức dựa trên ngôn ngữ và quốc gia thông qua cách sử dụng queriesForWhichOfficial.
Bạn không thể kiểm soát được cách Twiddler sắp xếp lại kết quả của mình, nhưng hiểu được cơ chế hoạt động của nó có thể giúp bạn giải thích tốt hơn về những biến động về thứ hạng hoặc về những “thứ hạng không thể giải thích”. Việc thường xuyên xem xét SERP và ghi chú các loại kết quả là rất có giá trị.
Ví dụ, bạn có thường xuyên thấy một số lượng bài đăng trên diễn đàn hoặc blog nhất định, ngay cả với các cụm từ tìm kiếm khác nhau không? Có bao nhiêu kết quả là giao dịch, thông tin hoặc điều hướng? Các tên miền giống nhau có xuất hiện nhiều lần không hay chúng thay đổi tùy theo những thay đổi nhỏ trong cụm từ tìm kiếm?
Nếu bạn nhận thấy chỉ có một vài cửa hàng trực tuyến được Google đưa vào kết quả, thì việc thử xếp hạng với một trang web bán hàng tương tự có thể mang lại hiệu quả kém. Thay vào đó, hãy cân nhắc tập trung vào những nội dung hướng đến thông tin nhiều hơn.
Người đánh giá chất lượng của Google và RankLab
Hàng ngàn người đánh giá chất lượng làm việc cho Google ở trên toàn thế giới để đánh giá một số kết quả tìm kiếm nhất định và thử nghiệm các thuật toán hoặc bộ lọc mới trước khi chúng được tiến hành “triển khai”.
Google giải thích rằng: “Xếp hạng của họ không ảnh hưởng trực tiếp đến thứ hạng”.
Về cơ bản thì điều này là đúng, nhưng những phiếu bầu này gây ra các tác động gián tiếp đáng kể đến với thứ hạng.
Cách thức hoạt động như sau: Người đánh giá nhận được URL hoặc cụm từ tìm kiếm (kết quả tìm kiếm) từ hệ thống và tiến hành trả lời các câu hỏi được xác định trước, thường được đánh giá trên thiết bị di động.
Ví dụ, họ có thể được hỏi, “Có rõ ràng ai đã viết nội dung này và khi nào không? Tác giả có chuyên môn về chủ đề này không?” Câu trả lời cho những câu hỏi này được lưu trữ và sử dụng để tiến hành đào tạo các thuật toán học máy. Các thuật toán này sẽ tiến hành phân tích các đặc điểm của các trang tốt và đáng tin cậy so với các trang ít tin cậy hơn.
Chính vì vậy, thay vì dựa vào các thành viên nhóm tìm kiếm của Google để tạo tiêu chí cho xếp hạng, các thuật toán sẽ sử dụng học sâu để xác định xem các mẫu dựa trên quá trình đào tạo do chính người đánh giá cung cấp.
Ví dụ, mọi người đánh giá một nội dung là đáng tin cậy, nếu nó bao gồm hình ảnh của tác giả, tên đầy đủ và chứa liên kết tiểu sử LinkedIn. Các trang mà thiếu các tính năng này thì sẽ được coi là kém tin cậy hơn.
Nếu một mạng nơ-ron được đào tạo trên nhiều tính năng trang cùng với các xếp hạng “Có” hoặc “Không” này, nó sẽ xác định đặc điểm này chính là một yếu tố chính. Sau một số lần chạy thử nghiệm tích cực, thường kéo dài ít nhất 30 ngày, mạng có thể bắt đầu sử dụng tính năng này làm tín hiệu để xếp hạng. Do đó, các trang có chứa hình ảnh tác giả, tên đầy đủ và liên kết LinkedIn thì đều có thể được tăng thứ hạng, có khả năng thông qua Twiddler, trong khi các trang không có các tính năng này thì có thể bị mất giá trị.
Quan điểm chính thức của Google là không tập trung vào tác giả có thể phù hợp với kịch bản này. Tuy nhiên, thông tin bị rò rỉ đã giúp tiết lộ các thuộc tính như: isAuthor và các khái niệm như “dấu vân tay tác giả” thông qua thuộc tính AuthorVectors, giúp phân biệt hoặc nhận dạng được idiolect (cách sử dụng thuật ngữ và công thức riêng lẻ) của tác giả.
Đánh giá của người đánh giá được biên soạn thành điểm “sự hài lòng về thông tin” (IS). Mặc dù nhiều người đánh giá đóng góp, điểm IS chỉ khả dụng cho một phần nhỏ URL. Đối với các trang khác có mẫu tương tự, điểm này được ngoại suy cho mục đích xếp hạng.
Google lưu ý, “Nhiều tài liệu không có lượt nhấp chuột nhưng có thể quan trọng”. Khi không thể ngoại suy, hệ thống sẽ tự động gửi tài liệu đến người đánh giá để tiến hành tạo điểm.
Thuật ngữ “vàng” được đề cập liên quan đến người đánh giá chất lượng, cho thấy có thể có một số tiêu chuẩn vàng cho một số tài liệu hoặc những loại tài liệu nhất định. Như vậy, việc tuân thủ kỳ vọng của người kiểm tra có thể giúp trang của bạn đạt được tiêu chuẩn vàng này. Ngoài ra, có khả năng một hoặc nhiều Twiddlers có thể cung cấp sự thúc đẩy đáng kể cho DocID được coi là “vàng”, có khả năng đưa chúng vào top 10.
Người đánh giá chất lượng thường không phải là nhân viên toàn thời gian của Google. Họ có thể làm việc thông qua các công ty bên ngoài. Ngược lại, các chuyên gia của Google hoạt động trong RankLab, nơi họ tiến hành các thử nghiệm, phát triển Twiddlers mới và đánh giá liệu những Twiddlers này hay những Twiddlers đã được tinh chỉnh có giúp cải thiện chất lượng kết quả hay chỉ lọc thư rác.
Các Twiddlers đã được chứng minh và hiệu quả sau đó sẽ được tích hợp vào hệ thống Mustang, nơi sử dụng các thuật toán phức tạp, chuyên sâu về tính toán và có sự kết nối với nhau.
Nhưng người dùng muốn gì? NavBoost có thể giải quyết vấn đề đó!
Tài liệu “pencil” của chúng tôi vẫn chưa thành công hoàn toàn. Trong Superroot, một hệ thống cốt lõi khác là NavBoost đóng vai trò quan trọng trong việc xác định thứ tự của kết quả tìm kiếm. NavBoost sử dụng “slices” để quản lý các tập dữ liệu khác nhau cho tìm kiếm ở trên thiết bị di động, máy tính để bàn và cục bộ.
Mặc dù Google đã chính thức phủ nhận việc sử dụng các lượt nhấp chuột của người dùng cho mục đích xếp hạng, tuy nhiên các tài liệu của FTC đã tiết lộ một email nội bộ hướng dẫn rằng việc xử lý dữ liệu lượt nhấp chuột phải được tiến hành bảo mật.
Trong trường hợp này, chúng ta không nên coi Google là kẻ dối trá, vì việc từ chối sử dụng dữ liệu nhấp chuột liên quan đến hai khía cạnh chính. Thứ nhất, việc thừa nhận việc sử dụng dữ liệu nhấp chuột có thể gây ra sự phẫn nộ lớn của giới truyền thông về các mối quan ngại về quyền riêng tư, mô tả Google như một “con bạch tuộc dữ liệu” theo dõi hoạt động trực tuyến của người dùng.
Tuy nhiên, mục đích đằng sau của việc sử dụng các dữ liệu nhấp chuột chính là để có được các số liệu thống kê có liên quan, không phải để theo dõi từng người dùng. Mặc dù, những người ủng hộ bảo vệ dữ liệu có thể có những quan điểm khác, nhưng quan điểm này giúp giải thích cho việc tại sao Google lại từ chối.
Các tài liệu của FTC xác nhận rằng dữ liệu nhấp chuột được sử dụng cho mục đích xếp hạng và thường xuyên đề cập đến hệ thống NavBoost trong bối cảnh này (54 lần trong phiên điều trần ngày 18 tháng 4 năm 2023). Và một phiên điều trần chính thức năm 2012 cũng đã tiết lộ rằng dữ liệu nhấp chuột ảnh hưởng đến thứ hạng.

Hình 5: Kể từ tháng 8 năm 2012, dữ liệu nhấp chuột đã chính thức thay đổi thứ hạng.
Người ta đã xác định rằng: cả hành vi nhấp chuột vào kết quả tìm kiếm và lưu lượng truy cập trên các trang web hoặc các trang đều ảnh hưởng đến thứ hạng. Google có thể dễ dàng đánh giá hành vi tìm kiếm, bao gồm tìm kiếm, nhấp chuột, tìm kiếm lặp lại và nhấp chuột lặp lại, trực tiếp trong SERP.
Có suy đoán rằng: Google có thể suy ra dữ liệu chuyển động tên miền từ Google Analytics, khiến một số người tránh sử dụng hệ thống này. Tuy nhiên, suy đoán này không hoàn toàn đúng.
Bởi, Google Analytics không cung cấp quyền truy cập vào tất cả dữ liệu giao dịch cho một tên miền. Quan trọng hơn chính là với hơn 60% người dùng sử dụng trình duyệt Google Chrome (hơn ba tỷ người dùng), Google thu thập dữ liệu về một phần đáng kể hoạt động trên web.
Điều này khiến Chrome trở thành một thành phần quan trọng trong việc phân tích các chuyển động trên web, như đã nêu trong các phiên điều trần. Ngoài ra, các tín hiệu Core Web Vitals được thu thập chính thức thông qua Chrome và tổng hợp thành giá trị “chromeInTotal”.
Sự công khai tiêu cực liên quan đến “giám sát” là một lý do cho việc Google từ chối, trong khi một lý do khác chính là mối lo ngại rằng việc đánh giá dữ liệu nhấp chuột và di chuyển có thể khuyến khích những kẻ xấu tiến hành gửi thư rác và kẻ lừa đảo tạo ra lưu lượng truy cập bằng cách sử dụng hệ thống bot để tiến hành thao túng thứ hạng.
– Một số số liệu được lưu trữ bao gồm badClicks và goodClicks. Khoảng thời gian người tìm kiếm ở lại trang đích và thông tin về số lượng trang khác mà họ tiến hành xem ở đó và vào thời điểm nào (dữ liệu Chrome) rất có thể được đưa vào đánh giá này.
– Một đường vòng ngắn đến kết quả tìm kiếm và quay lại nhanh kết quả tìm kiếm và nhấp thêm vào các kết quả khác có thể làm tăng số lần nhấp không tốt. Kết quả tìm kiếm có lần nhấp “tốt” cuối cùng trong phiên tìm kiếm này được ghi lại là lastLongestClick.
– Dữ liệu được nén lại (tức là cô đọng lại) để được chuẩn hóa về mặt thống kê và ít bị thao túng hơn.
– Nếu một trang, một nhóm trang hoặc trang bắt đầu của một tên miền thường có số liệu khách truy cập tốt (dữ liệu Chrome), điều này có tác động tích cực thông qua NavBoost. Bằng cách phân tích các mẫu chuyển động trong một tên miền hoặc giữa các tên miền, thậm chí có thể giúp xác định hướng dẫn người dùng tốt như thế nào thông qua điều hướng.
– Vì Google đo toàn bộ phiên tìm kiếm, về mặt lý thuyết, thậm chí trong những trường hợp cực đoan, có thể nhận ra rằng một tài liệu hoàn toàn khác được coi là phù hợp hơn với truy vấn tìm kiếm của người dùng. Nếu người tìm kiếm rời khỏi tên miền mà họ đã nhấp vào ở trong kết quả tìm kiếm trong một tìm kiếm, và tiến hành đi đến một tên miền khác (có thể được liên kết ở đó) và vẫn tiến hành ở đó như là phần cuối có thể nhận dạng được của tìm kiếm, thì tài liệu “cuối” này có thể sẽ được đưa lên phía trước thông qua NavBoost ở trong tương lai, với điều kiện là nó có sẵn trong tập hợp vòng chọn. Tuy nhiên, điều này sẽ yêu cầu một tín hiệu có liên quan về mặt thống kê vô cùng mạnh mẽ từ nhiều người tìm kiếm.
Trước tiên, hãy xem xét các lần nhấp ở trong kết quả tìm kiếm. Mỗi vị trí xếp hạng trong SERP có tỷ lệ nhấp trung bình dự kiến (CTR), đóng vai trò là chuẩn mực hiệu suất. Ví dụ, theo phân tích của Johannes Beus trình bày tại CAMPIXX năm nay ở Berlin, Vị trí hữu cơ số 1 sẽ nhận được trung bình 26,2% lượt nhấp, trong khi Vị trí 2 chỉ nhận được 15,5%.
Nếu CTR thực tế của một đoạn trích thấp hơn đáng kể so với tỷ lệ mong đợi, hệ thống NavBoost sẽ ghi nhận sự khác biệt này và tiến hành điều chỉnh lại thứ hạng của DocID sao cho phù hợp. Nếu một kết quả trước đây tạo ra nhiều hoặc ít lượt nhấp hơn đáng kể so với dự kiến, NavBoost sẽ di chuyển tài liệu lên hoặc xuống trong thứ hạng khi cần (xem Hình 6).
Cách tiếp cận này vô cùng có ý nghĩa, vì các lần nhấp về cơ bản chính là đại diện cho phiếu bầu của người dùng về mức độ liên quan của kết quả tìm kiếm dựa trên tiêu đề, mô tả và tên miền. Khái niệm này thậm chí còn được tiến hành trình bày chi tiết trong các tài liệu chính thức, như minh họa trong Hình 7.
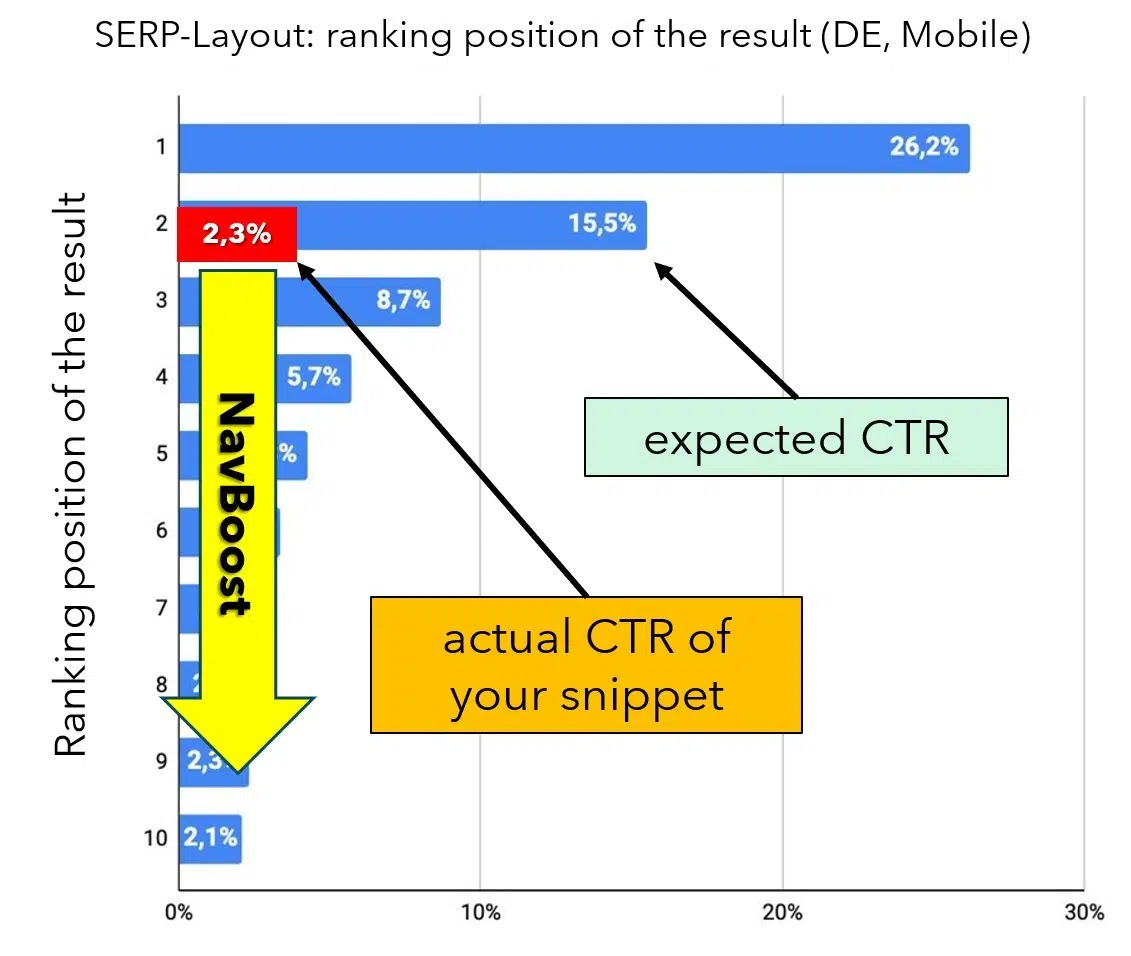
Hình 6: Nếu “expected_CRT lệch đáng kể so với giá trị thực tế, thứ hạng sẽ được điều chỉnh cho phù hợp. (Nguồn dữ liệu: J. Beus, SISTRIX, với lớp phủ biên tập)
Hình 7: Slide từ bài thuyết trình của Google (Nguồn: Bản trình bày tại phiên tòa – UPX0228, Hoa Kỳ và các tiểu bang nguyên đơn kiện Google LLC)
Vì tài liệu “pencil” của chúng tôi vẫn còn mới nên chưa có giá trị CTR nào khả dụng. Không rõ liệu độ lệch CTR có bị bỏ qua đối với các tài liệu không có dữ liệu hay không, nhưng điều này có vẻ khả thi, vì mục tiêu chính là kết hợp phản hồi của người dùng. Ngoài ra, CTR ban đầu có thể được ước tính dựa trên các giá trị khác, tương tự như cách xử lý hệ số chất lượng trong Google Ads.
– Các chuyên gia SEO và nhà phân tích dữ liệu từ lâu đã báo cáo rằng họ đã nhận thấy hiện tượng sau khi theo dõi một cách toàn diện tỷ lệ nhấp chuột của chính họ: Nếu một tài liệu cho truy vấn tìm kiếm mới xuất hiện trong top 10 và CTR giảm đáng kể so với kỳ vọng, bạn có thể thấy thứ hạng sẽ giảm trong vòng vài ngày (tùy thuộc vào khối lượng tìm kiếm).
– Ngược lại, thứ hạng thường tăng nếu CTR cao hơn đáng kể so với thứ hạng. Bạn chỉ có một thời gian ngắn để phản ứng và điều chỉnh lại đoạn trích nếu CTR kém (thường là bằng cách tối ưu hóa về tiêu đề và mô tả) để thu thập được nhiều lượt nhấp chuột hơn từ người dùng. Nếu không, vị trí của bạn sẽ xấu đi và sau đó không dễ để có thể lấy lại. Nếu một tài liệu chứng minh được giá trị của nó, thì nó có thể ở lại. Nếu người tìm kiếm không thích nó, nó sẽ biến mất một lần nữa. Liệu điều này có thực sự liên quan đến NavBoost hay không vẫn chưa thực sự rõ ràng.
Dựa trên thông tin bị rò rỉ, có vẻ như Google sử dụng dữ liệu mở rộng từ “môi trường” của trang để ước tính tín hiệu cho các trang mới, trang chưa được biết đến.
Ví dụ, NearestSeedversion gợi ý rằng PageRank của trang chủ HomePageRank_NS được chuyển đến các trang mới cho đến khi chúng phát triển PageRank của riêng mình. Ngoài ra, pnavClicks dường như được sử dụng để ước tính và chỉ định xác suất nhấp chuột thông qua điều hướng.
Việc tính toán và cập nhật PageRank sẽ tốn nhiều thời gian và tính toán chuyên sâu, đó là lý do tại sao số liệu PageRank_NS có thể được sử dụng thay thế. “NS” là viết tắt của “hạt giống gần nhất”, nghĩa là một tập hợp các trang liên quan chia sẻ giá trị PageRank, nó sẽ được áp dụng tạm thời hoặc đôi khi là vĩnh viễn cho các trang mới.
Các giá trị từ các trang lân cận cũng được sử dụng cho các tín hiệu quan trọng khác, giúp các trang mới có thể leo lên thứ hạng mặc dù thiếu lưu lượng truy cập hoặc liên kết ngược đáng kể. Nhiều tín hiệu không được ghi nhận theo thời gian thực, nhưng có thể liên quan đến độ trễ đáng kể.
– Bản thân Google đã đưa ra một ví dụ tốt về sự tươi mới ở trong phiên điều trần. Ví dụ, nếu bạn tìm kiếm “Stanley Cup”, kết quả tìm kiếm thường có hình chiếc cốc nổi tiếng. Tuy nhiên, khi các trận đấu khúc côn cầu trên băng Stanley Cup đang diễn ra, NavBoost sẽ điều chỉnh kết quả sao cho ưu tiên thông tin về các trận đấu, phản ánh những thay đổi trong hành vi tìm kiếm và nhấp chuột.
– Độ mới không đề cập đến các tài liệu mới mà là những thay đổi trong hành vi tìm kiếm. Theo Google, có hơn một tỷ hành vi mới trong SERP mỗi ngày. Vì vậy, mọi tìm kiếm và mọi nhấp chuột đều góp phần vào quá trình học hỏi của Google. Google nhận ra những thay đổi chi tiết trong ý định của tìm kiếm và liên tục tiến hành điều chỉnh hệ thống. Và chính điều này đã tạo ra ảo tưởng rằng Google thực sự “hiểu” những gì người tìm kiếm muốn.
Theo những phát hiện mới nhất, số liệu về lượt nhấp chuột vào tài liệu dường như sẽ được lưu trữ và đánh giá trong khoảng thời gian 13 tháng.
Vì tên miền giả định của chúng tôi có số liệu thống kê về lượng truy cập mạnh và lượng truy cập trực tiếp đáng kể từ quảng cáo, với tư cách là một thương hiệu nổi tiếng (đây là một tín hiệu tích cực), nên tài liệu “pencil” mới của chúng tôi được hưởng lợi từ các tín hiệu thuận lợi của các trang cũ và đã thành công.
Kết quả là, NavBoost nâng thứ hạng của chúng tôi từ vị trí thứ 14 lên vị trí thứ 5, đưa chúng tôi vào “vòng tròn xanh” hay chính top 10. Danh sách top 10 này, bao gồm tài liệu của chúng tôi, sau đó được chuyển tiếp đến Máy chủ web của Google cùng với chín kết quả tự nhiên khác.
– Trái với kỳ vọng, Google thực sự không tiến hành cung cấp nhiều kết quả tìm kiếm được cá nhân hóa. Các thử nghiệm có thể đã chỉ ra rằng việc mô hình hóa hành vi của người dùng và thực hiện các thay đổi đối với hành vi đó mang lại kết quả tốt hơn so với việc đánh giá sở thích cá nhân của từng người dùng.
– Dự đoán thông qua mạng nơ-ron hiện phù hợp hơn với chúng ta so với lịch sử lướt web và nhấp chuột của chính chúng ta. Tuy nhiên, sở thích cá nhân, như sở thích về nội dung video, vẫn sẽ được đưa vào kết quả cá nhân.
GWS: Nơi mọi thứ kết thúc và bắt đầu một khởi đầu mới
Máy chủ web Google (GWS) chịu trách nhiệm tiến hành lắp ráp và cung cấp trang kết quả tìm kiếm (SERP). Trang này bao gồm 10 liên kết màu xanh lam, cùng với quảng cáo, hình ảnh, chế độ xem Google Maps, phần “Mọi người cũng hỏi” và các thành phần khác.
Hệ thống Tangram tiến hành xử lý việc tối ưu hóa không gian hình học, tính toán lượng không gian mà mỗi phần tử cần và có bao nhiêu kết quả phù hợp với các “hộp” có sẵn. Sau đó, hệ thống Glue sẽ tiến hành sắp xếp các phần tử này vào đúng vị trí của chúng.
Tài liệu “pencil” của chúng tôi, hiện đang ở vị trí thứ 5 trong kết quả hữu cơ. Tuy nhiên, hệ thống CookBook có thể tiến hành can thiệp vào phút cuối. Hệ thống này bao gồm FreshnessNode, InstantGlue (phản ứng trong khoảng thời gian 24 giờ với độ trễ khoảng 10 phút) và InstantNavBoost. Các thành phần này tạo ra các tín hiệu bổ sung liên quan đến tính thời sự và có thể tiến hành điều chỉnh thứ hạng vào những khoảnh khắc cuối cùng trước khi trang được hiển thị.
Giả sử một chương trình truyền hình Đức về 250 năm của Faber-Castell và những huyền thoại xung quanh từ “pencil” bắt đầu phát sóng. Trong vòng vài phút, hàng ngàn người xem cầm điện thoại thông minh hoặc máy tính bảng của họ để tìm kiếm trực tuyến. FreshnessNode phát hiện ra sự gia tăng ở trong các tìm kiếm cho “pencil” và lưu ý rằng người dùng đang tìm kiếm thông tin thay vì tiến hành mua hàng, nó sẽ điều chỉnh thứ hạng sao cho phù hợp.
Trong tình huống đặc biệt này, InstantNavBoost tiến hành xóa tất cả các kết quả giao dịch và thay thế chúng bằng các kết quả chứa thông tin theo thời gian thực. Sau đó, InstantGlue sẽ tiến hành cập nhật “vòng tròn màu xanh lam”, khiến tài liệu hướng đến doanh số trước đây của chúng tôi bị loại khỏi bảng xếp hạng hàng đầu và được thay thế bằng các kết quả có tính liên quan hơn.
Hình 8: Một chương trình truyền hình về nguồn gốc của từ “pencil” để kỷ niệm 250 năm thành lập Faber-Castell, một nhà sản xuất bút chì nổi tiếng của Đức.
Và chính cái kết giả định cho hành trình xếp hạng này đã giúp minh họa cho một điểm quan trọng: Để đạt được thứ hạng cao không chỉ đơn thuần là có một tài liệu tuyệt vời hay triển khai đúng các biện pháp SEO với các nội dung chất lượng cao.
Xếp hạng của bạn có thể bị ảnh hưởng bởi nhiều yếu tố khác, bao gồm thay đổi trong hành vi tìm kiếm, tín hiệu mới cho các tài liệu khác và các tình huống đang thay đổi. Do đó, điều quan trọng là phải nhận ra rằng: có một tài liệu tuyệt vời và làm tốt công việc SEO chỉ chiếm một phần của bối cảnh xếp hạng rộng lớn và năng động.
Quá trình biên soạn kết quả tìm kiếm diễn ra cực kỳ phức tạp, chịu ảnh hưởng của hàng ngàn tín hiệu. Với nhiều thử nghiệm được SearchLab thực hiện trực tiếp bằng Twiddler, ngay cả các liên kết ngược đến tài liệu của bạn cũng có thể bị ảnh hưởng.
Những tài liệu này có thể được chuyển từ HiveMind đến các cấp độ ít quan trọng hơn, như SSD hoặc thậm chí là TeraGoogle, điều này có thể làm suy yếu hoặc loại bỏ tác động của chúng đối với thứ hạng. Điều này có thể làm thay đổi thang xếp hạng ngay cả khi không có gì thay đổi với tài liệu của riêng bạn.
John Mueller của Google đã nhấn mạnh rằng: việc giảm thứ hạng thường không có nghĩa là bạn đã làm sai điều gì đó. Những thay đổi trong hành vi của người tìm kiếm hoặc các yếu tố khác có thể tạo ra thay đổi hiệu suất của kết quả.
Ví dụ, nếu người tìm kiếm bắt đầu thích các thông tin chi tiết hơn và văn bản ngắn hơn theo thời gian, NavBoost sẽ tự động điều chỉnh thứ hạng sao cho phù hợp. Tuy nhiên, điểm IR trong hệ thống Alexandria hoặc Ascorer vẫn sẽ không thay đổi.
Một điểm chính cần lưu ý là SEO phải được hiểu trong bối cảnh rộng hơn. Tối ưu hóa tiêu đề hoặc nội dung sẽ không hiệu quả nếu như tài liệu và mục đích tìm kiếm của nó không thống nhất.
Tác động của Twiddlers và NavBoost lên thứ hạng thường có thể vượt trội hơn các tối ưu hóa truyền thống trên trang, trên Website hoặc ngoài trang Web. Nếu các hệ thống này hạn chế khả năng hiển thị của tài liệu, các cải tiến bổ sung trên trang sẽ có tác dụng tối thiểu.
Tuy nhiên, hành trình của chúng tôi không hoàn toàn thất bại. Tác động của chương trình truyền hình về “pencil” chỉ là tạm thời. Khi đợt tìm kiếm tăng đột biến lắng xuống, FreshnessNode sẽ không còn ảnh hưởng đến thứ hạng của chúng tôi nữa và chúng tôi sẽ được trở lại vị trí thứ 5.
Khi chúng tôi khởi động lại chu kỳ thu thập dữ liệu nhấp chuột, CTR dự kiến khoảng 4% cho Vị trí 5 (dựa trên Johannes Beus từ SISTRIX). Nếu chúng tôi có thể duy trì CTR này, chúng tôi sẽ được nằm trong Top 10.
Những điểm chính của SEO
– Đa dạng hóa nguồn lưu lượng truy cập: Đảm bảo rằng trang của bạn nhận được lưu lượng truy cập từ nhiều nguồn khác nhau, không chỉ từ công cụ tìm kiếm. Lưu lượng truy cập có thể đến từ các kênh ít rõ ràng hơn, như nền tảng truyền thông xã hội, cũng có giá trị. Bởi, ngay cả khi trình thu thập thông tin của Google không thể truy cập vào một số trang nhất định, Google vẫn có thể tiến hành theo dõi số lượng khách truy cập vào trang web của bạn thông qua các nền tảng như Chrome hoặc URL trực tiếp.
– Xây dựng nhận thức về thương hiệu và tên miền: Luôn nỗ lực tăng cường nhận diện về thương hiệu hoặc tên miền của bạn. Người dùng càng quen thuộc với tên của bạn thì khả năng họ nhấp vào trang web của bạn ở trong kết quả tìm kiếm sẽ càng cao. Xếp hạng cho nhiều từ khóa đuôi dài cũng có thể giúp thúc đẩy khả năng hiển thị tên miền của bạn. Rò rỉ của Google cho thấy rằng: “quyền hạn của trang web” là một tín hiệu xếp hạng, vì vậy việc xây dựng danh tiếng cho thương hiệu của bạn có thể giúp cải thiện về thứ hạng tìm kiếm của bạn.
– Hiểu ý định tìm kiếm: Để đáp ứng tốt hơn nhu cầu của khách truy cập, hãy cố gắng hiểu ý định tìm kiếm và các hành trình của họ. Sử dụng các công cụ như: Semrush hoặc SimilarWeb để xem khách truy cập của bạn đến từ đâu và họ sẽ đi đâu sau khi truy cập vào trang web của bạn. Phân tích các tên miền này, chúng có cung cấp thông tin mà các trang đích của bạn còn thiếu không? Tiến hành thêm nội dung còn thiếu này để trở thành “điểm đến cuối cùng” trong hành trình tìm kiếm của các khách truy cập. Hãy nhớ rằng, Google tiến hành theo dõi các phiên tìm kiếm có liên quan và biết chính xác những gì người tìm kiếm đang tìm kiếm và họ đã tìm kiếm ở đâu.
– Tối ưu hóa tiêu đề và mô tả của bạn để cải thiện CTR: Bắt đầu bằng cách xem xét CTR hiện tại của bạn và thực hiện các điều chỉnh thích hợp để giúp tăng sức hấp dẫn khi nhấp chuột. Viết hoa một số từ quan trọng có thể giúp chúng nổi bật về mặt trực quan, có khả năng thúc đẩy về CTR. Tiêu đề đóng vai trò quan trọng trong việc xác định xem trang của bạn có đang xếp hạng tốt cho cụm từ tìm kiếm hay không, vì vậy việc tối ưu hóa tiêu đề nên là ưu tiên quan trọng hàng đầu.
– Đánh giá nội dung ẩn: Nếu bạn sử dụng accordion để “ẩn” nội dung quan trọng và cần tiến hành nhấp để hiển thị nó, hãy kiểm tra xem các trang này có tỷ lệ thoát cao hơn so với mức trung bình hay không. Khi người tìm kiếm không thể thấy ngay rằng họ đang ở đúng nơi và cần nhấp nhiều lần, khả năng tín hiệu nhấp tiêu cực đôi khi sẽ tăng lên.
– Xóa các trang kém hiệu quả: Các trang không ai truy cập (phân tích web) hoặc không đạt thứ hạng tốt ở trong thời gian dài nên được xóa nếu cần thiết. Các tín hiệu xấu cũng sẽ được truyền đến các trang lân cận. Nếu bạn xuất bản một tài liệu mới ở trong một cụm trang “xấu”, trang mới sẽ có ít cơ hội. “deltaPageQuality” rõ ràng thực sự đo lường sự khác biệt về mặt định tính giữa các tài liệu riêng lẻ trong một miền hoặc cụm.
– Cải thiện cấu trúc trang: Cấu trúc trang rõ ràng, điều hướng dễ dàng và ấn tượng đầu tiên mạnh mẽ là điều cần thiết để trang Web của bạn đạt được thứ hạng cao, thường là nhờ NavBoost.
– Tối đa hóa sự tương tác: Khách truy cập ở lại trang web của bạn càng lâu thì tín hiệu mà tên miền của bạn được gửi đi càng tốt, và sẽ mang lại lợi ích cho tất cả các trang con của bạn. Mục tiêu là trở thành điểm đến cuối cùng bằng cách cung cấp tất cả thông tin hữu ích mà người dùng cần để khách truy cập không phải tiến hành tìm kiếm ở nơi khác.
– Mở rộng nội dung hiện có thay vì liên tục tạo nội dung mới: Cập nhật và cải thiện nội dung hiện tại của bạn có thể mang lại hiệu quả hơn. ContentEffortScore đo lường nỗ lực tạo ra một tài liệu, với các yếu tố như hình ảnh chất lượng cao, video, công cụ và nội dung độc đáo đều sẽ góp phần tạo nên tín hiệu quan trọng này.
– Căn chỉnh tiêu đề của bạn với nội dung mà chúng giới thiệu: Đảm bảo rằng các tiêu đề (trung gian) phản ánh chính xác các khối văn bản theo sau. Phân tích theo chủ đề, sử dụng các kỹ thuật như nhúng (vector hóa văn bản), hiệu quả hơn trong việc xác định xem tiêu đề và nội dung có khớp chính xác hay không so với các phương pháp thuần túy từ vựng.
– Sử dụng phân tích web: Các công cụ như Google Analytics cho phép bạn theo dõi hiệu quả mức độ tương tác của khách truy cập và xác định cũng như giúp giải quyết mọi khoảng cách. Hãy đặc biệt chú ý đến tỷ lệ thoát trang của trang đích. Nếu tỷ lệ thoát này quá cao, hãy điều tra các nguyên nhân tiềm ẩn và thực hiện ngay các hành động khắc phục. Hãy nhớ rằng Google có thể truy cập vào dữ liệu này thông qua trình duyệt Chrome.
– Nhắm mục tiêu vào các từ khóa ít cạnh tranh: Bạn cũng có thể tập trung vào việc xếp hạng tốt cho các từ khóa ít cạnh tranh trước, từ đó dễ dàng xây dựng các tín hiệu tích cực từ người dùng hơn.
– Trau dồi các liên kết ngược chất lượng: Tập trung vào các liên kết đến từ các trang gần đây hoặc có lưu lượng truy cập cao được lưu trữ trong HiveMind, vì chúng cung cấp các tín hiệu có giá trị hơn. Các liên kết đến từ các trang có ít lưu lượng truy cập hoặc ít tương tác sẽ mang lại ít hiệu quả hơn. Ngoài ra, các liên kết ngược từ các trang trong cùng một quốc gia và các liên kết có chủ đề liên quan đến nội dung của bạn sẽ có lợi hơn. Hãy lưu ý rằng các liên kết ngược “độc hại”, có tác động tiêu cực đến điểm số của bạn, vì vậy nên tránh nó.
– Chú ý đến ngữ cảnh xung quanh các liên kết: Văn bản trước và sau liên kết, không chỉ riêng văn bản neo, được xem xét để xếp hạng. Đảm bảo văn bản tự nhiên chảy quanh liên kết. Tránh sử dụng các cụm từ chung chung như “nhấp vào đây”, vốn không mang lại hiệu quả trong hơn hai mươi năm.
– Lưu ý đến những hạn chế của công cụ Disavow: Công cụ Disavow, được sử dụng để vô hiệu hóa các liên kết xấu, không được đề cập trong bản rò rỉ. Có vẻ như các thuật toán không xem xét đến nó và nó chủ yếu phục vụ mục đích làm tài liệu cho những người chống thư rác.
– Xem xét chuyên môn của tác giả: Nếu bạn sử dụng tài liệu tham khảo của tác giả, hãy đảm bảo rằng chúng cũng được công nhận trên các trang web khác và chứng minh được chuyên môn có liên quan. Có ít tác giả nhưng có trình độ cao thì sẽ tốt hơn là có nhiều tác giả nhưng lại thiếu sự uy tín. Theo bằng sáng chế, Google có thể đánh giá nội dung dựa trên chuyên môn của tác giả, phân biệt giữa chuyên gia và người bình thường.
– Tạo nội dung độc quyền, hữu ích, toàn diện và có cấu trúc tốt: Điều này đặc biệt quan trọng đối với các trang chính. Hãy thể hiện chuyên môn thực sự của bạn về chủ đề này và nếu có thể, hãy cung cấp các bằng chứng về điều đó.
Bài viết được dịch tại SEL và đăng tải duy nhất lên SEOMxh.com
NGUỒN: https://searchengineland.com/how-google-search-ranking-works-445141